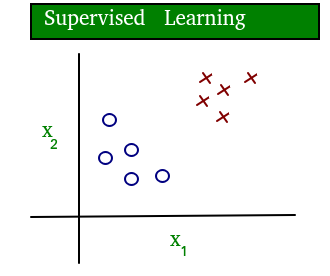
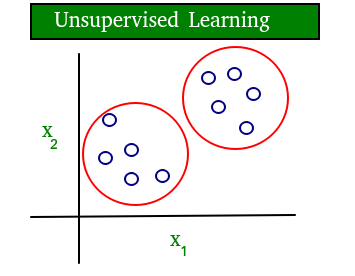
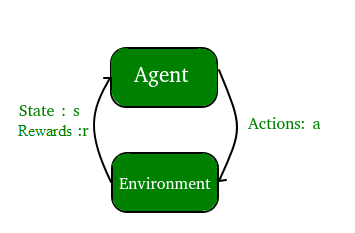
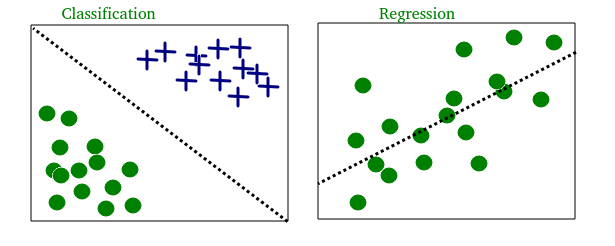
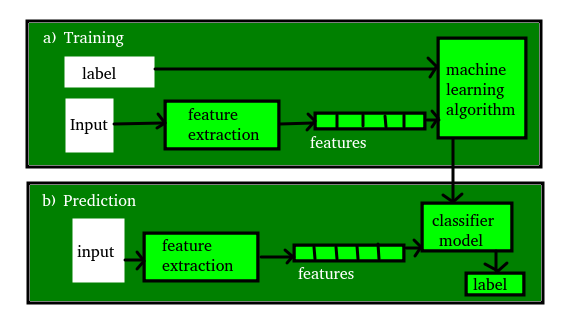
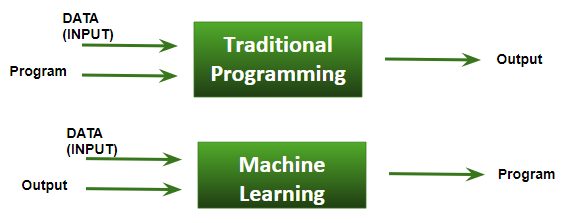
Aprendizado de máquina, como o nome sugere, é a ciência da programação de um computador por meio do qual
eles são capazes de aprender com diferentes tipos de dados. Uma definição mais geral dada por Arthur Samuel
é - “Aprendizado de máquina é o campo de estudo que dá aos computadores a capacidade de aprender sem serem
programados explicitamente”. Eles normalmente são usados para resolver vários tipos de problemas da vida.
Antigamente, as pessoas costumavam realizar tarefas de aprendizado de máquina codificando manualmente todos
os algoritmos e fórmulas matemáticas e estatísticas. Isso tornava o processo demorado, tedioso e
ineficiente. Mas nos dias modernos, tornou-se muito mais fácil e eficiente em comparação com os velhos
tempos por várias bibliotecas, estruturas e módulos Python. Hoje, Python é uma das linguagens de programação
mais populares para essa tarefa e substituiu muitas linguagens na indústria, uma das razões é sua vasta
coleção de bibliotecas. As bibliotecas Python usadas no aprendizado de máquina são:
- Numpy
- Scipy
- Scikit-learn
- Theano
- TensorFlow
- Keras
- PyTorch
- Pandas
- Matplotlib
Numpy
NumPy é uma biblioteca python muito popular para grandes matrizes multidimensionais e processamento de
matrizes, com a ajuda de uma grande coleção de funções matemáticas de alto nível. É muito útil para cálculos
científicos fundamentais em Aprendizado de Máquina. É particularmente útil para álgebra linear, transformada
de Fourier e recursos de números aleatórios. Bibliotecas de última geração, como TensorFlow, usam NumPy
internamente para manipulação de tensores.
# Programa python usando
# a biblioteca Numpy para
# realizar algumas operações básicas
import numpy as np
# Criando duas matriz de duas dimensões
x = np.array([[1, 2], [3, 4]])
y = np.array([[5, 6], [7, 8]])
# Criando duas matrizes de um dimensão
v = np.array([9, 10])
w = np.array([11, 12])
# Produto interno de vetores
print(np.dot(v, w), "\n")
# Produto de matriz e vetor
print(np.dot(x, v), "\n")
# Matriz e produto da matriz
print(np.dot(x, y))
Saída:
219
[29 67]
[[19 22]
[43 50]]
Para obter mais detalhes, consulte Numpy
SciPy
SciPy é uma biblioteca muito popular entre os entusiastas do Aprendizado de Máquina, pois contém diferentes módulos para otimização, álgebra linear, integração e estatística. Há uma diferença entre a biblioteca SciPy e a pilha SciPy. O SciPy é um dos pacotes principais que compõem a pilha do SciPy. SciPy também é muito útil para manipulação de imagens.
# Script python usando Scipy
# para manipulação de imagens
from scipy.misc import imread, imsave, imresize
# Converte uma imagem JPEG para array numpy
img = imread('D:/Programs/cat.jpg') # Caminho da imagem
print(img.dtype, img.shape)
# Tingindo a imagem
img_tint = img * [1, 0.45, 0.3]
# Salvando a imagem tingida
imsave('D:/Programs/cat_tinted.jpg', img_tint)
$ redimencionando a imagem tingida para 300 x 300 pixels
img_tint_resize = imresize(img_tint, (300, 300))
# Salvando a imagem tingida e redimencionada
imsave('D:/Programs/cat_tinted_resized.jpg', img_tint_resize)
Imagem original:
Imagem matizada:
Imagem matizada redimensionada:
Para obter mais detalhes, consulte a documentação.
Scikit-learn
Skikit-learn é uma das bibliotecas de ML mais populares para algoritmos de ML clássicos. É construído em cima de duas bibliotecas Python básicas, viz., NumPy e SciPy. O Scikit-learn oferece suporte à maioria dos algoritmos de aprendizagem supervisionados e não supervisionados. O Scikit-learn também pode ser usado para mineração e análise de dados, o que o torna uma ótima ferramenta para quem está começando com ML.
# Script Python usando Scikit-learn para classificador de árvore de decisão
# Classificador de árvore de decisão de amostra
from sklearn import datasets
from sklearn import metrics
from sklearn.tree import DecisionTreeClassifier
# carregar os conjuntos de dados da íris
dataset = datasets.load_iris()
# ajustar um modelo CART aos dados
model = DecisionTreeClassifier()
model.fit(dataset.data, dataset.target)
print(model)
# fazer previsões
expected = dataset.target
predicted = model.predict(dataset.data)
# resumir o ajuste do modelo
print(metrics.classification_report(expected, predicted))
print(metrics.confusion_matrix(expected, predicted))
Saída:
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
precision recall f1-score support
0 1.00 1.00 1.00 50
1 1.00 1.00 1.00 50
2 1.00 1.00 1.00 50
micro avg 1.00 1.00 1.00 150
macro avg 1.00 1.00 1.00 150
weighted avg 1.00 1.00 1.00 150
[[50 0 0]
[ 0 50 0]
[ 0 0 50]]
Para obter mais detalhes, consulte a documentação.
Theano
Todos nós sabemos que o aprendizado de máquina é basicamente matemática e estatística. Theano é uma biblioteca python popular usada para definir, avaliar e otimizar expressões matemáticas envolvendo matrizes multidimensionais de maneira eficiente. Consegue-se otimizando a utilização da CPU e GPU. É amplamente utilizado para teste de unidade e autoverificação para detectar e diagnosticar diferentes tipos de erros. Theano é uma biblioteca muito poderosa que tem sido usada em projetos científicos de grande escala computacionalmente intensivos por um longo tempo, mas é simples e acessível o suficiente para ser usada por indivíduos em seus próprios projetos.
# Programa Python usando Theano para calcular uma função logística
import theano
import theano.tensor as T
x = T.dmatrix('x')
s = 1 / (1 + T.exp(-x))
logistic = theano.function([x], s)
logistic([[0, 1], [-1, -2]])
Saída:
array([[0.5, 0.73105858],
[0.26894142, 0.11920292]])
Para obter mais detalhes, consulte a documentação.
TensorFlow
TensorFlow é uma biblioteca de código aberto muito popular para computação numérica de alto desempenho desenvolvida pela equipe do Google Brain no Google. Como o nome sugere, Tensorflow é uma estrutura que envolve a definição e execução de cálculos envolvendo tensores. Ele pode treinar e executar redes neurais profundas que podem ser usadas para desenvolver vários aplicativos de IA. O TensorFlow é amplamente utilizado no campo de pesquisa e aplicação de aprendizado profundo.
# Programa Python usando TensorFlow para multiplicar duas matrizes
import tensorflow as tf
# Inicializando duas constantes
x1 = tf.constant([1, 2, 3, 4])
x2 = tf.constant([5, 6, 7, 8])
# Multiplicando
result = tf.multiply(x1, x2)
# Inicializando a sessão
sess = tf.Session()
# Mostarndo o resultado
print(sess.run(result))
# Encerrando a sessão
sess.close()
Saída:
[5 12 21 32]
Para obter mais detalhes, consulte a documentação.
Keras
Keras é uma biblioteca de aprendizado de máquina muito popular para Python. É uma API de redes neurais de alto nível capaz de ser executada em TensorFlow, CNTK ou Theano. Ele pode ser executado perfeitamente na CPU e GPU. Keras torna realmente para iniciantes em ML construir e projetar uma rede neural. Uma das melhores coisas sobre Keras é que ele permite uma prototipagem fácil e rápida.
Para obter mais detalhes, consulte a documentação.
PyTorch
PyTorch é uma biblioteca de aprendizado de máquina de código aberto popular para Python baseada no Torch, que é uma biblioteca de aprendizado de máquina de código aberto que é implementada em C com um wrapper em Lua. Ele tem uma ampla escolha de ferramentas e bibliotecas que oferecem suporte a Visão por Computador, Processamento de Linguagem Natural (PNL) e muitos outros programas de ML. Ele permite que os desenvolvedores realizem cálculos em tensores com aceleração de GPU e também ajuda na criação de gráficos computacionais.
# Programa Python usando PyTorch para definir tensores,
# ajustar uma rede de duas camadas para dados aleatórios
# e calcular a perda
import torch
dtype = torch.float
device = torch.device("cpu")
# device = torch.device("cuda:0") para utilizar gpu
# N é o tamanho do lote; D_in é a dimensão de entrada;
# H é uma dimensão oculta; D_out é a dimensão de saída.
N, D_in, H, D_out = 64, 1000, 100, 10
# Criando dados de entrada e saída aleatórios
x = torch.randn(N, D_in, device = device, dtype = dtype)
y = torch.randn(N, D_out, device = device, dtype = dtype)
# Inicializa os pesos de forma aleatória
w1 = torch.randn(D_in, H, device = device, dtype = dtype)
w2 = torch.randn(H, D_out, device = device, dtype = dtype)
learning_rate = 1e-6
for t in range(500):
h = x.mm(w1)
h_relu = h.clamp(min = 0)
y_pred = h_relu.mm(w2)
loss = (y_pred - y).pow(2).sum().item()
print(t, loss)
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h < 0] = 0
grad_w1 = x.t().mm(grad_h)
# Update weights using gradient descent
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
Saída:
0 47168344.0
1 46385584.0
2 43153576.0
...
...
...
497 3.987660602433607e-05
498 3.945609932998195e-05
499 3.897604619851336e-05
Para obter mais detalhes, consulte a documentação.
Pandas
Pandas é uma biblioteca Python popular para análise de dados. Não está diretamente relacionado ao aprendizado de máquina. Como sabemos, o conjunto de dados deve ser preparado antes do treinamento. Nesse caso, o Pandas é útil porque foi desenvolvido especificamente para extração e preparação de dados. Ele fornece estruturas de dados de alto nível e uma ampla variedade de ferramentas para análise de dados. Ele fornece muitos métodos embutidos para tatear, combinar e filtrar dados.
# Programa Python usando Pandas para organizar um determinado conjunto de dados em uma tabela
import pandas as pd
data = {"country": ["Brazil", "Russia", "India", "China", "South Africa"],
"capital": ["Brasilia", "Moscow", "New Dehli", "Beijing", "Pretoria"],
"area": [8.516, 17.10, 3.286, 9.597, 1.221],
"population": [200.4, 143.5, 1252, 1357, 52.98] }
data_table = pd.DataFrame(data)
print(data_table)
Saída:
country capital area population
0 Brazil Brasilia 8.516 200.40
1 Russia Moscow 17.100 143.50
2 India New Dehli 3.286 1252.00
3 China Beijing 9.597 1357.00
4 South Africa Pretoria 1.221 52.98
Matplotlib
Matpoltlib é uma biblioteca Python muito popular para visualização de dados. Como o Pandas, não está diretamente relacionado ao aprendizado de máquina. É particularmente útil quando um programador deseja visualizar os padrões nos dados. É uma biblioteca de plotagem 2D usada para criar gráficos e plotagens 2D. Um módulo chamado pyplot facilita a plotagem de programadores, pois fornece recursos para controlar estilos de linha, propriedades de fonte, eixos de formatação etc. Ele fornece vários tipos de gráficos e plotagens para visualização de dados, viz., Histograma, gráficos de erro, bate-papos de barra, etc.
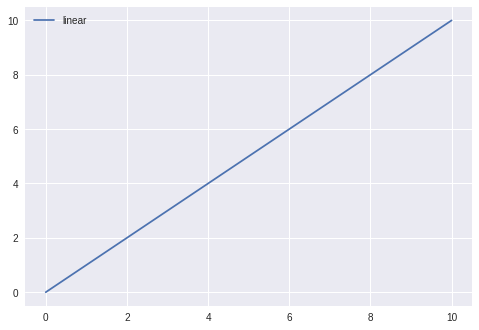
# Python program using Matplotib for forming a linear plot
import matplotlib.pyplot as plt
import numpy as np
# preparando os dados
x = np.linspace(0, 10, 100)
# Criando o grafico
plt.plot(x, x, label='linear')
# Adicionando legenda
plt.legend()
# Mostrando grafico
plt.show()
Saída:
Artigo escrito por Rahul_Roy e traduzido por Acervo Lima de Best Python libraries for Machine Learning.