Este artigo discute as categorias de problemas de aprendizado de máquina e terminologias usadas no campo do aprendizado de máquina.
Tipos de problemas de aprendizado de máquina
Existem várias maneiras de classificar os problemas de aprendizado de máquina. Aqui, discutimos os mais óbvios.
1. Com base na natureza do "sinal" ou "feedback" de aprendizagem disponível para um sistema de aprendizagem.
- Aprendizagem supervisionada: O computador é apresentado com exemplos de entradas e suas saídas desejadas, fornecidas por um “professor”, e o objetivo é aprender uma regra geral que mapeia entradas em saídas. O processo de treinamento continua até que o modelo atinja o nível desejado de precisão nos dados de treinamento. Alguns exemplos da vida real são:
- Classificação de imagens: Você treina com imagens / rótulos. Então, no futuro, você fornece uma nova imagem esperando que o computador reconheça o novo objeto.
- Previsão / regressão do mercado: você treina o computador com dados históricos do mercado e pede que ele preveja o novo preço no futuro.
- Aprendizagem não supervisionada: nenhum rótulo é dado ao algoritmo de aprendizagem, deixando-o sozinho para encontrar a estrutura em sua entrada. É usado para agrupar a população em grupos diferentes. A aprendizagem não supervisionada pode ser um objetivo em si (descobrir padrões ocultos nos dados).
- Clustering: você pede ao computador para separar dados semelhantes em clusters, isso é essencial na pesquisa e na ciência.
- Visualização de alta dimensão: Use o computador para nos ajudar a visualizar dados de alta dimensão.
- Modelos gerativos: depois que um modelo captura a distribuição de probabilidade de seus dados de entrada, ele será capaz de gerar mais dados. Isso pode ser muito útil para tornar seu classificador mais robusto.
Um diagrama simples que esclarece o conceito de aprendizagem supervisionada e não supervisionada é mostrado abaixo:
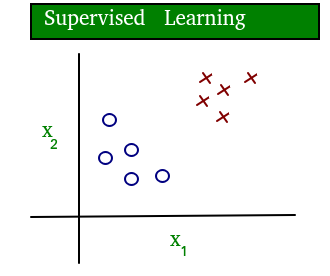
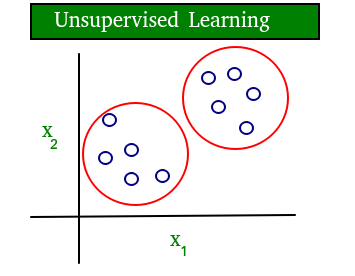
Como você pode ver claramente, os dados da aprendizagem supervisionada são rotulados, enquanto os dados da aprendizagem não supervisionada não são rotulados.
- Aprendizagem semissupervisionada: os problemas em que você tem uma grande quantidade de dados de entrada e apenas alguns dos dados são rotulados são chamados de problemas de aprendizagem semissupervisionada. Esses problemas ficam entre o aprendizado supervisionado e o não supervisionado. Por exemplo, um arquivo de fotos onde apenas algumas das imagens estão etiquetadas (por exemplo, cachorro, gato, pessoa) e a maioria não está etiquetada.
- Aprendizagem por reforço: um programa de computador interage com um ambiente dinâmico no qual deve realizar um determinado objetivo (como dirigir um veículo ou jogar um jogo contra um oponente). O programa recebe feedback em termos de recompensas e punições à medida que navega no espaço do problema.
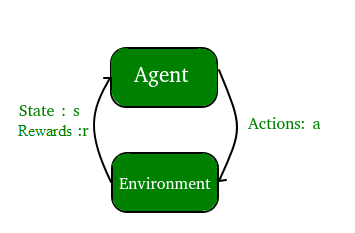
2. Com base na "saída" desejada de um sistema aprendido por máquina
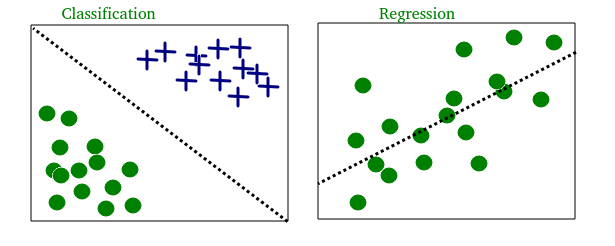
- Classificação: as entradas são divididas em duas ou mais classes, e o aluno deve produzir um modelo que atribua entradas não vistas a uma ou mais (classificação multi-rótulo) dessas classes. Normalmente, isso é resolvido de forma supervisionada. A filtragem de spam é um exemplo de classificação, onde as entradas são mensagens de e-mail (ou outras) e as classes são “spam” e “não spam”.
- Regressão: também é um problema de aprendizado supervisionado, mas as saídas são contínuas ao invés de discretas. Por exemplo, prever os preços das ações usando dados históricos.
Um exemplo de classificação e regressão em dois conjuntos de dados diferentes é mostrado abaixo:
-
Clustering: aqui, um conjunto de entradas deve ser dividido em grupos. Ao
contrário da classificação, os grupos não são conhecidos de antemão, o que torna essa tarefa
normalmente não supervisionada.
Como você pode ver no exemplo abaixo, os pontos do conjunto de dados fornecidos foram divididos em grupos identificáveis pelas cores vermelho, verde e azul. - Estimativa de densidade: A tarefa é encontrar a distribuição de entradas em algum espaço.
- Redução de dimensionalidade: simplifica as entradas mapeando-as em um espaço de dimensão inferior. A modelagem de tópicos é um problema relacionado, em que um programa recebe uma lista de documentos em linguagem humana e tem a tarefa de descobrir quais documentos cobrem tópicos semelhantes.

Com base nessas tarefas / problemas de aprendizado de máquina, temos uma série de algoritmos que são usados para realizar essas tarefas. Alguns algoritmos de aprendizado de máquina comumente usados são Regressão Linear, Regressão Logística, Árvore de Decisão, SVM (máquinas de vetor de suporte), Naive Bayes, KNN (K vizinhos mais próximos), K-Means, Floresta Aleatória, etc.
Observação: todos esses algoritmos serão abordados em artigos futuros.
Terminologias de aprendizado de máquina
- Modelo
Um modelo é uma representação específica aprendida de dados aplicando algum algoritmo de aprendizado de máquina. Um modelo também é chamado de hipótese . - Recurso
Um recurso é uma propriedade individual mensurável de nossos dados. Um conjunto de recursos numéricos pode ser convenientemente descrito por um vetor de recursos . Os vetores de recursos são alimentados como entrada para o modelo. Por exemplo, para prever uma fruta, pode haver características como cor, cheiro, sabor, etc.
Nota: A escolha de características informativas, discriminativas e independentes é uma etapa crucial para algoritmos eficazes. Geralmente empregamos um extrator de recursos para extrair os recursos relevantes dos dados brutos. - Alvo (rótulo)
Uma variável ou rótulo alvo é o valor a ser previsto por nosso modelo. Para o exemplo de fruta discutido na seção de recursos, o rótulo com cada conjunto de entrada seria o nome da fruta como maçã, laranja, banana, etc. - Treinamento
A ideia é dar um conjunto de entradas (recursos) e suas saídas esperadas (rótulos), portanto, após o treinamento, teremos um modelo (hipótese) que mapeará os novos dados para uma das categorias treinadas. - Predição Assim
que nosso modelo estiver pronto, ele pode ser alimentado com um conjunto de entradas para as quais fornecerá uma saída prevista (rótulo).
A figura mostrada abaixo esclarece os conceitos acima:
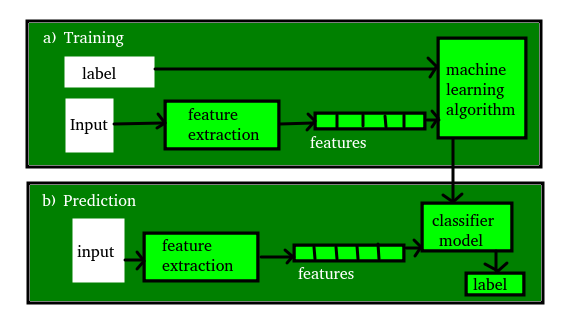
Artigos relacionados:
Referências:
- https://en.wikipedia.org/wiki/Machine_learning
- https://leonardoaraujosantos.gitbooks.io/artificial-inteligence/
- http://machinelearningmastery.com/data-terminology-in-machine-learning/
Artigo escrito por Nikhil Kumar e traduzido por Acervo Lima de Getting started with Machine Learning.
0 comentários:
Postar um comentário