Vamos usar um conjunto de dados real do TRAI para analisar as velocidades de dados móveis e tentar ver as velocidades médias de uma operadora ou estado específico naquele mês. Isso também mostrará como o Pandas pode ser facilmente usado em quaisquer dados do mundo real para obter resultados interessantes.
Sobre o conjunto de dados
A Autoridade Reguladora de Telecomunicações da Índia (TRAI) lança um conjunto de dados mensal das velocidades da internet que mede por meio do aplicativo MySpeed (TRAI). Isso inclui testes de velocidade iniciados pelo próprio usuário ou testes periódicos em segundo plano feitos pelo aplicativo. Tentaremos analisar esse conjunto de dados e ver as velocidades médias de uma determinada operadora ou estado naquele mês.
Inspecionando a estrutura bruta dos dados
- Acesse TRAI MySpeed Portal e baixe o arquivo csv do mês mais recente na seção Download. Você também pode baixar o arquivo csv usado neste artigo: sept18_publish.csv ou sept18_publish_drive.csv.
- Abra este arquivo de planilha.
NOTA:
Como o conjunto de dados é enorme, o software pode avisar que não foi possível carregar todas as linhas. Isto é bom. Além disso, se você estiver usando o Microsoft Excel, pode haver um aviso sobre a abertura de um arquivo SYLK. Esse erro pode ser ignorado, pois é um bug comum no Excel. Agora, vamos dar uma olhada na organização dos dados.
- 1ª coluna é do Operador de Rede - JIO, Airtel etc.
- 2ª coluna é da Tecnologia de Rede - 3G ou 4G.
- A 3ª coluna é o tipo de teste iniciado - upload ou download.
- A quarta coluna é a velocidade medida em kilobytes por segundo.
- A 5ª coluna é a intensidade do sinal durante a medição.
- A 6ª coluna é a Área de Serviço Local (LSA) , ou o círculo onde o teste foi feito - Delhi, Orissa etc. Iremos nos referir a isso simplesmente como 'estados'.
NOTA:
A intensidade do sinal pode ter valores na (Not Available) devido a alguns dispositivos incapazes de capturar o sinal. Ignoraremos o uso desse parâmetro em nossos cálculos para tornar as coisas mais simples. No entanto, ele pode ser facilmente adicionado como uma condição durante a filtragem.
Pacotes necessários
- pandas: um popular kit de ferramentas de análise de dados. Muito poderoso para processar grandes conjuntos de dados.
- Numpy: fornece operações rápidas e eficientes em matrizes de dados homogêneos. Usaremos isso junto com pandas e matplotlib.
- Matplotlib: é uma biblioteca de plotagem. Usaremos sua função de gráfico de barras para fazer gráficos de barras.
Vamos começar a analisar os dados
Etapa #1: importe os pacotes e defina algumas constantes.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# vamos definir algumas constantes
# nome do conjunto de dados csv
DATASET_FILENAME = 'sept18_publish.csv'
# definir o operador a ser filtrado
CONST_OPERATOR = 'JIO'
# definir o estado a ser filtrado
CONST_STATE = 'Delhi'
# definir a tecnologia a ser filtrada
CONST_TECHNOLOGY = '4G'Etapa #2: Defina algumas listas que armazenarão os resultados calculados finais, de forma que possam ser passados para a função de plotagem de barras facilmente. O estado (ou operador), velocidade de download e velocidade de upload serão armazenados em série de forma que para um índice, o estado (ou operador), suas velocidades de download e upload correspondentes possam ser acessados.
Por exemplo, final_states[2], final_download_speeds[2] e final_upload_speeds[2] fornecerá os valores correspondentes para o 3º estado.
Etapa #3: Importe o arquivo usando a método read_csv() do pandas e armazene-o em 'codedf'. Isso criará um DataFrame do conteúdo do arquivo csv no qual trabalharemos.
df = pd.read_csv(DATASET_FILENAME)
# atribuir cabeçalhos para cada uma das colunas com base nos dados,
# o que nos permite acessar as colunas facilmente
df.columns = [
'Service Provider', 'Technology', 'Test Type',
'Data Speed', 'Signal Strength', 'State'
]Etapa #4: Primeiro, vamos encontrar todos os estados e operadores exclusivos neste conjunto de dados e armazená-los na lista de estados e operadores correspondentes.
Usaremos o método unique() do dataframe do pandas para selecionar os valores únicos.
# encontre e exiba os estados únicos
states = df['State'].unique()
print('ESTADOS encontrados: ', states)
# encontre e exiba os operadores exclusivos
operators = df['Service Provider'].unique()
print('OPERADORES encontrados: ', operators)Saída:
ESTADOS encontrados: ['Kerala' 'Rajasthan' 'Maharashtra' 'UP East' 'Karnataka' nan 'Madhya Pradesh' 'Kolkata' 'Bihar' 'Gujarat' 'UP West' 'Orissa' 'Tamil Nadu' 'Delhi' 'Assam' 'Andhra Pradesh' 'Haryana' 'Punjab' 'North East' 'Mumbai' 'Chennai' 'Himachal Pradesh' 'Jammu & Kashmir' 'West Bengal'] OPERADORES encontrados: ['IDEA' 'JIO' 'AIRTEL' 'VODAFONE' 'CELLONE']
Etapa #5: Definir a função fixed_operator, que manterá o operador constante e iterará por todos os estados disponíveis para aquele operador. Podemos construir uma função semelhante para um estado fixo.
# filtrar o operador e a tecnologia
# primeiro, pois isso será comum para todos
filtered = df[(df['Service Provider'] == CONST_OPERATOR) & (df['Technology'] == CONST_TECHNOLOGY)]
# iterar em cada um dos estados
for state in states:
# criar um novo dataframe que contém
# apenas os dados do estado atual
base = filtered[filtered['State'] == state]
# filtrar apenas velocidades de download com base no tipo de teste
down = base[base['Test Type'] == 'download']
# filtrar apenas velocidades de upload com base no tipo de teste
up = base[base['Test Type'] == 'upload']
# calcular a média das velocidades na coluna
# Data Speed usando o método pandas.mean()
avg_down = down['Data Speed'].mean()
# calcular a média das velocidades
# na coluna Velocidade de dados
avg_up = up['Data Speed'].mean()
# descarte os valores se a média não for um número (nan)
# e acrescente apenas os válidos
if (pd.isnull(avg_down) or pd.isnull(avg_up)):
down, up = 0, 0
else:
final_states.append(state)
final_download_speeds.append(avg_down)
final_upload_speeds.append(avg_up)
# saída de impressão com até 2 casas decimais
print(str(state) + ' -- Média de Download: ' +
str('%.2f' % avg_down) +
' Média de Upload: ' + str('%.2f' % avg_up))Saída:
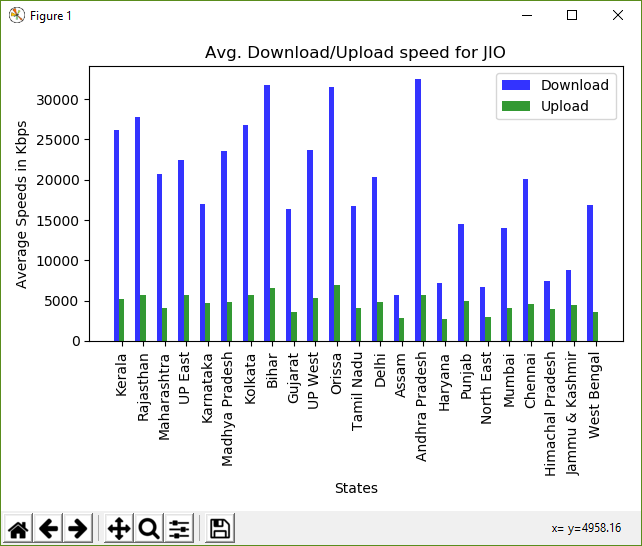
Kerala -- Média de Download: 26129.27 Média de Upload: 5193.46 Rajasthan -- Média de Download: 27784.86 Média de Upload: 5736.18 Maharashtra -- Média de Download: 20707.88 Média de Upload: 4130.46 UP East -- Média de Download: 22451.35 Média de Upload: 5727.95 Karnataka -- Média de Download: 16950.36 Média de Upload: 4720.68 Madhya Pradesh -- Média de Download: 23594.85 Média de Upload: 4802.89 Kolkata -- Média de Download: 26747.80 Média de Upload: 5655.55 Bihar -- Média de Download: 31730.54 Média de Upload: 6599.45 Gujarat -- Média de Download: 16377.43 Média de Upload: 3642.89 UP West -- Média de Download: 23720.82 Média de Upload: 5280.46 Orissa -- Média de Download: 31502.05 Média de Upload: 6895.46 Tamil Nadu -- Média de Download: 16689.28 Média de Upload: 4107.44 Delhi -- Média de Download: 20308.30 Média de Upload: 4877.40 Assam -- Média de Download: 5653.49 Média de Upload: 2864.47 Andhra Pradesh -- Média de Download: 32444.07 Média de Upload: 5755.95 Haryana -- Média de Download: 7170.63 Média de Upload: 2680.02 Punjab -- Média de Download: 14454.45 Média de Upload: 4981.15 North East -- Média de Download: 6702.29 Média de Upload: 2966.84 Mumbai -- Média de Download: 14070.97 Média de Upload: 4118.21 Chennai -- Média de Download: 20054.47 Média de Upload: 4602.35 Himachal Pradesh -- Média de Download: 7436.99 Média de Upload: 4020.09 Jammu & Kashmir -- Média de Download: 8759.20 Média de Upload: 4418.21 West Bengal -- Média de Download: 16821.17 Média de Upload: 3628.78
Traçando os dados
Use o método arange() da biblioteca Numpy que retorna valores uniformemente espaçados dentro de um determinado intervalo. Aqui, passando o comprimento final_stateslista, obtemos valores de 0 ao número de estados na lista como [0, 1, 2, 3...]
Podemos então usar esses índices para traçar uma barra naquele local. A segunda barra é plotada deslocando a localização da primeira barra pela largura da barra.
fig, ax = plt.subplots()
# a largura de cada barra
bar_width = 0.25
# a opacidade de cada barra
opacity = 0.8
# guarda as posições
index = np.arange(len(final_states))
# o método plt.bar() recebe a posição das barras,
# dados a serem plotados, largura de cada barra e
# alguns outros parâmetros opcionais, como a opacidade e cor
# traçar as barras de download
bar_download = plt.bar(
index, final_download_speeds,
bar_width, alpha=opacity,
color='b', label='Download'
)
# traçar as barras de upload
bar_upload = plt.bar(
index + bar_width, final_upload_speeds,
bar_width, alpha=opacity, color='g',
label='Upload'
)
# Título do gráfico
plt.title('Média da velocidade de Download/Upload para ' + str(CONST_OPERATOR))
# rótulo do eixo x
plt.xlabel('States')
# rótulo do eixo y
plt.ylabel('Velocidades médias em Kbps')
# o rótulo abaixo de cada uma das barras, correspondendo aos estados
plt.xticks(index + bar_width, final_states, rotation=90)
# desenhe a legenda
plt.legend()
# faça o layout do gráfico estreito
plt.tight_layout()
# mostre o gráfico
plt.show()Saída:
Comparando dados de dois meses
Vamos pegar alguns dados de outro mês também e representá-los juntos para observar a diferença nas velocidades de dados.
Para este exemplo, o conjunto de dados do mês anterior será o mesmo sept18_publish.csv e o conjunto de dados do mês seguinte será oct18_publish.csv.
Só precisamos executar as mesmas etapas novamente. Leia os dados do outro mês. Filtre-o para dataframes subsequentes e, em seguida, plote-o usando um método ligeiramente diferente. Durante a plotagem das barras, incrementaremos a 3ª e 4ª barras (correspondentes ao upload e download do segundo arquivo) em 2 e 3 vezes a largura da barra, de modo que fiquem em suas posições corretas.
Abaixo está a implementação para comparar 2 meses de dados:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import time
# mês mais velho
DATASET_FILENAME = 'https://myspeed.trai.gov.in/download/sept18_publish.csv'
# mês mais recente
DATASET_FILENAME2 = 'https://myspeed.trai.gov.in/download/oct18_publish.csv'
CONST_OPERATOR = 'JIO'
CONST_STATE = 'Delhi'
CONST_TECHNOLOGY = '4G'
# leia o arquivo com o pandas e armazene como dataframe
df = pd.read_csv(DATASET_FILENAME)
df2 = pd.read_csv(DATASET_FILENAME2)
# atribuir nomes de coluna
df.columns = [
'Service Provider', 'Technology', 'Test Type',
'Data Speed', 'Signal Strength', 'State'
]
df2.columns = [
'Service Provider', 'Technology', 'Test Type',
'Data Speed', 'Signal Strength', 'State'
]
# encontre e exiba os estados únicos
states = df['State'].unique()
print('ESTADOS encontrados: ', states)
# encontre e exiba os operadores exclusivos
operators = df['Service Provider'].unique()
print('OPERADORES encontrados: ', operators)
# define listas
final_download_speeds = []
final_upload_speeds = []
final_download_speeds_second =[]
final_upload_speeds_second = []
final_states = []
final_operators = []
# atribuir nomes de coluna aos dados
df.columns = [
'Service Provider', 'Technology', 'Test Type',
'Data Speed', 'Signal Strength', 'State'
]
df2.columns = [
'Service Provider', 'Technology', 'Test Type',
'Data Speed', 'Signal Strength', 'State'
]
print('\n\nComparando dados para' + str(CONST_OPERATOR))
filtered = df[(df['Service Provider'] == CONST_OPERATOR)
& (df['Technology'] == CONST_TECHNOLOGY)]
filtered2 = df2[(df2['Service Provider'] == CONST_OPERATOR)
& (df2['Technology'] == CONST_TECHNOLOGY)]
for state in states:
base = filtered[filtered['State'] == state]
# calcular a média das velocidades de download
avg_down = base[base['Test Type'] ==
'download']['Data Speed'].mean()
# calcular a média das velocidades de upload
avg_up = base[base['Test Type'] ==
'upload']['Data Speed'].mean()
base2 = filtered2[filtered2['State'] == state]
# calcular a média das velocidades de download
avg_down2 = base2[base2['Test Type'] ==
'download']['Data Speed'].mean()
# calcular a média das velocidades de upload
avg_up2 = base2[base2['Test Type'] ==
'upload']['Data Speed'].mean()
# descarte os valores se a média não for um número (nan)
# e acrescente apenas as velocidades necessárias
if (pd.isnull(avg_down) or pd.isnull(avg_up) or
pd.isnull(avg_down2) or pd.isnull(avg_up2)):
avg_down = 0
avg_up = 0
avg_down2 = 0
avg_up2 = 0
else:
final_states.append(state)
final_download_speeds.append(avg_down)
final_upload_speeds.append(avg_up)
final_download_speeds_second.append(avg_down2)
final_upload_speeds_second.append(avg_up2)
print('Mais velho: ' + str(state) + ' -- Download: ' +
str('%.2f' % avg_down) + ' Upload: ' +
str('%.2f' % avg_up))
print('Recente: ' + str(state) + ' -- Download: ' +
str('%.2f' % avg_down2) + ' Upload: ' +
str('%.2f' % avg_up2))
fig, ax = plt.subplots()
index = np.arange(len(final_states))
bar_width = 0.2
opacity = 0.8
rects1 = plt.bar(index, final_download_speeds,
bar_width, alpha=opacity, color='b',
label='Download do mês anterior')
rects2 = plt.bar(index + bar_width, final_upload_speeds,
bar_width, alpha=opacity, color='g',
label='Upload do mês anterior')
rects3 = plt.bar(index + 2 * bar_width, final_download_speeds_second,
bar_width, alpha=opacity, color='y',
label='Download do mês mais recente')
rects4 = plt.bar(index + 3 * bar_width, final_upload_speeds_second,
bar_width, alpha=opacity, color='r',
label='Upload do mês mais recente')
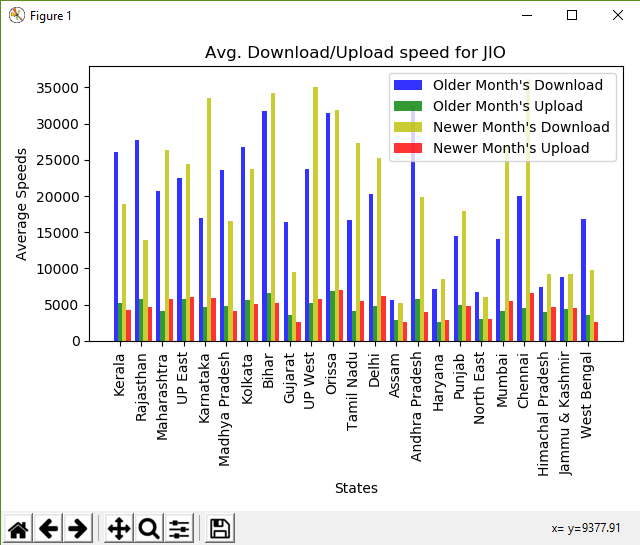
plt.xlabel('States')
plt.ylabel('Velocidades Médias')
plt.title('Velocidade média de download/upload para '
+ str(CONST_OPERATOR))
plt.xticks(index + bar_width, final_states, rotation=90)
plt.legend()
plt.tight_layout()
plt.show()Resultado:
ESTADOS encontrados: ['Kerala' 'Rajasthan' 'Maharashtra' 'UP East' 'Karnataka' nan 'Madhya Pradesh' 'Kolkata' 'Bihar' 'Gujarat' 'UP West' 'Orissa' 'Tamil Nadu' 'Delhi' 'Assam' 'Andhra Pradesh' 'Haryana' 'Punjab' 'North East' 'Mumbai' 'Chennai' 'Himachal Pradesh' 'Jammu & Kashmir' 'West Bengal'] OPERADORES encontrados: ['IDEA' 'JIO' 'AIRTEL' 'VODAFONE' 'CELLONE'] Comparando dados paraJIO Mais velho: Kerala -- Download: 26129.27 Upload: 5193.46 Recente: Kerala -- Download: 18917.46 Upload: 4290.13 Mais velho: Rajasthan -- Download: 27784.86 Upload: 5736.18 Recente: Rajasthan -- Download: 13973.66 Upload: 4721.17 Mais velho: Maharashtra -- Download: 20707.88 Upload: 4130.46 Recente: Maharashtra -- Download: 26285.47 Upload: 5848.77 Mais velho: UP East -- Download: 22451.35 Upload: 5727.95 Recente: UP East -- Download: 24368.81 Upload: 6101.20 Mais velho: Karnataka -- Download: 16950.36 Upload: 4720.68 Recente: Karnataka -- Download: 33521.31 Upload: 5871.38 Mais velho: Madhya Pradesh -- Download: 23594.85 Upload: 4802.89 Recente: Madhya Pradesh -- Download: 16614.49 Upload: 4135.70 Mais velho: Kolkata -- Download: 26747.80 Upload: 5655.55 Recente: Kolkata -- Download: 23761.85 Upload: 5153.29 Mais velho: Bihar -- Download: 31730.54 Upload: 6599.45 Recente: Bihar -- Download: 34196.09 Upload: 5215.58 Mais velho: Gujarat -- Download: 16377.43 Upload: 3642.89 Recente: Gujarat -- Download: 9557.90 Upload: 2684.55 Mais velho: UP West -- Download: 23720.82 Upload: 5280.46 Recente: UP West -- Download: 35035.84 Upload: 5797.93 Mais velho: Orissa -- Download: 31502.05 Upload: 6895.46 Recente: Orissa -- Download: 31826.96 Upload: 6968.59 Mais velho: Tamil Nadu -- Download: 16689.28 Upload: 4107.44 Recente: Tamil Nadu -- Download: 27306.54 Upload: 5537.58 Mais velho: Delhi -- Download: 20308.30 Upload: 4877.40 Recente: Delhi -- Download: 25198.16 Upload: 6228.81 Mais velho: Assam -- Download: 5653.49 Upload: 2864.47 Recente: Assam -- Download: 5243.34 Upload: 2676.69 Mais velho: Andhra Pradesh -- Download: 32444.07 Upload: 5755.95 Recente: Andhra Pradesh -- Download: 19898.16 Upload: 4002.25 Mais velho: Haryana -- Download: 7170.63 Upload: 2680.02 Recente: Haryana -- Download: 8496.27 Upload: 2862.61 Mais velho: Punjab -- Download: 14454.45 Upload: 4981.15 Recente: Punjab -- Download: 17960.28 Upload: 4885.83 Mais velho: North East -- Download: 6702.29 Upload: 2966.84 Recente: North East -- Download: 6008.06 Upload: 3052.87 Mais velho: Mumbai -- Download: 14070.97 Upload: 4118.21 Recente: Mumbai -- Download: 26898.04 Upload: 5539.71 Mais velho: Chennai -- Download: 20054.47 Upload: 4602.35 Recente: Chennai -- Download: 36086.70 Upload: 6675.70 Mais velho: Himachal Pradesh -- Download: 7436.99 Upload: 4020.09 Recente: Himachal Pradesh -- Download: 9277.45 Upload: 4622.25 Mais velho: Jammu & Kashmir -- Download: 8759.20 Upload: 4418.21 Recente: Jammu & Kashmir -- Download: 9290.38 Upload: 4533.08 Mais velho: West Bengal -- Download: 16821.17 Upload: 3628.78 Recente: West Bengal -- Download: 9763.05 Upload: 2627.28
Acabamos de aprender como analisar alguns dados do mundo real e desenhar algumas observações interessantes a partir deles. Mas note que nem todos os dados serão tão bem formatados e simples de lidar, o Pandas torna incrivelmente fácil de trabalhar com esses conjuntos de dados.
Artigo escrito por sayantanm19 e traduzido por Acervolima de Analyzing Mobile Data Speeds from TRAI with Pandas.
0 comentários:
Postar um comentário