pandas é uma biblioteca de código aberto feita principalmente para trabalhar com dados relacionais ou rotulados de forma fácil e intuitiva. Ele fornece várias estruturas de dados e operações para manipular dados numéricos e séries temporais. Esta biblioteca é construída no topo da biblioteca NumPy. pandas é rápido e tem alto desempenho e produtividade para os usuários.
História
O pandas foi inicialmente desenvolvido por Wes McKinney em 2008, enquanto ele trabalhava na AQR Capital Management. Ele convenceu a AQR a permitir que ele abrisse o código-fonte dos pandas. Outro funcionário da AQR, Chang She, ingressou como o segundo maior colaborador da biblioteca em 2012. Com o passar do tempo, muitas versões de pandas foram lançadas. A última versão do pandas é 1.0.1.
Vantagens do pandas
- Rápido e eficiente para manipular e analisar dados.
- Dados de diferentes objetos de arquivo podem ser carregados.
- Fácil manuseio de dados ausentes (representados como NaN) em ponto flutuante, bem como dados de ponto não flutuante.
- Mutabilidade de tamanho: colunas podem ser inseridas e excluídas do DataFrame e objetos de dimensão superior.
- Fusão e junção de conjuntos de dados.
- Remodelagem flexível e dinamização de conjuntos de dados.
- Fornece funcionalidade de série temporal.
- Poderoso agrupamento por funcionalidade para realizar operações dividir-aplicar-combinar em conjuntos de dados.
Começando com a biblioteca pandas
Depois que a biblioteca pandas tiver sido instalada no sistema, você precisará importar a biblioteca. Este módulo é geralmente importado como o exemplo abaixo mostrar.
import pandas as pd
Aqui, o pd é conhecido como um alias para o pandas. No entanto, não é necessário importar a biblioteca usando alias, apenas ajuda a escrever menos quantidade de código toda vez que um método ou propriedade é chamado.
O pandas geralmente fornece duas estruturas de dados para manipulação de dados, são elas:
- Series
- DataFrame
Series
pandas Series é um array rotulado unidimensional capaz de conter dados de qualquer tipo (inteiro, string, float, objetos python, etc.). Os rótulos dos eixos são chamados coletivamente de índice. O pandas Series nada mais é do que uma coluna em uma planilha do Excel. Os rótulos não precisam ser exclusivos, mas devem ser do tipo hashable. O objeto é compatível com indexação inteira e baseada em rótulo e fornece uma série de métodos para executar operações envolvendo o índice.

Observação: para obter mais informações, consulte Python | pandas Series
Criando uma Series do pandas
No mundo real, uma série pandas será criada carregando os conjuntos de dados do armazenamento existente, o armazenamento pode ser banco de dados SQL, arquivo CSV e arquivo Excel. A série pandas pode ser criada a partir de listas, dicionário e de um valor escalar, etc.
Exemplo:
import pandas as pd import numpy as np # Cria uma series vázia ser = pd.Series() print(ser) # Uma matriz simples data = np.array(['g', 'e', 'e', 'k', 's']) ser = pd.Series(data) print(ser)
Saída:
Series([], dtype: float64) 0 g 1 e 2 e 3 k 4 s dtype: object
DataFrame
O DataFrame pandas é uma estrutura de dados tabular bidimensional mutável em tamanho, potencialmente heterogênea, com eixos rotulados (linhas e colunas). Um dataframe é uma estrutura de dados bidimensional, ou seja, os dados são alinhados de forma tabular em linhas e colunas. O DataFrame pandas consiste em três componentes principais: dados, linhas e colunas.
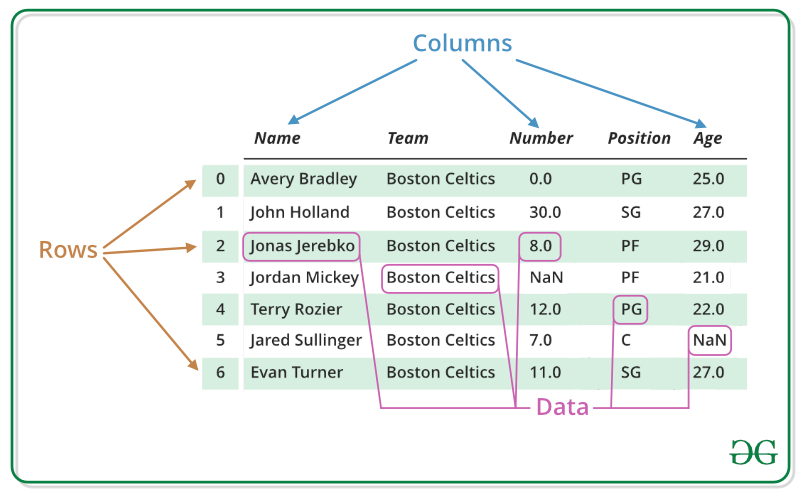
Observação: para obter mais informações, consulte Criando dataframes com pandas.
Criando um dataframe pandas
No mundo real, um DataFrame pandas será criado carregando os conjuntos de dados do armazenamento existente, o armazenamento pode ser banco de dados SQL, arquivo CSV e arquivo Excel. O DataFrame pandas pode ser criado a partir de listas, dicionário e de uma lista de dicionários, etc.
Exemplo:
import pandas as pd # Chamando o construtor do dataframe df = pd.DataFrame() print(df) # lista de strings lst = ['Acervo', 'Lima', 'o', 'melhor', 'em', 'programação'] # Chamando o construtor do dataframe com uma lista df = pd.DataFrame(lst) print(df)
Saída:
0
0 Acervo
1 Lima
2 o
3 melhor
4 em
5 programação
Observação: para obter mais informações, consulte Criando dataframes com pandas.
Por que o pandas é usado para ciência de dados
O pandas é geralmente usado para ciência de dados, mas você já se perguntou por quê? Isso ocorre porque o pandas é usado em conjunto com outras bibliotecas que são usadas para ciência de dados. É construído no topo da biblioteca NumPy, o que significa que muitas estruturas do NumPy são usadas ou replicadas no pandas. Os dados produzidos pelo pandas são frequentemente usados como entrada para funções de plotagem do Matplotlib, análise estatística no SciPy, algoritmo de aprendizado de máquina no Scikit-learn.
O programa pandas pode ser executado a partir de qualquer editor de texto, mas é recomendado usar o Jupyter Notebook para isso, pois o Jupyter tem a capacidade de executar o código em uma célula específica em vez de executar o arquivo inteiro. O Jupyter também oferece uma maneira fácil de visualizar dados e gráficos do pandas.
Observação: para obter mais informações sobre o Jupyter Notebook, consulte Como usar o Jupyter Notebook - um guia definitivo.
Artigo escripot por nikhilaggarwal3 e traduzido por Acervo Lima de Introduction to pandas in Python. Alguma alterações foram feitas.
0 comentários:
Postar um comentário