O método Series.str.join() do pandas é usado para juntar todos os elementos na lista presente em uma série com o delimitador passado. Como as strings também são uma matriz de caracteres (ou Lista de caracteres), portanto, quando esse método é aplicado a uma série de strings, a string é unida a cada caractere com o delimitador passado.
.str deve ser prefixado sempre antes de chamar este método para diferenciá-lo do método de string padrão do Python.
Sintaxe: Series.str.join(sep)
Parâmetro:
- sep: recebe uma string, junta os elementos com a string entre eles
Tipo de retorno: Uma Series com os elementos juntos
Para baixar o arquivo csv utilizado, clique aqui.
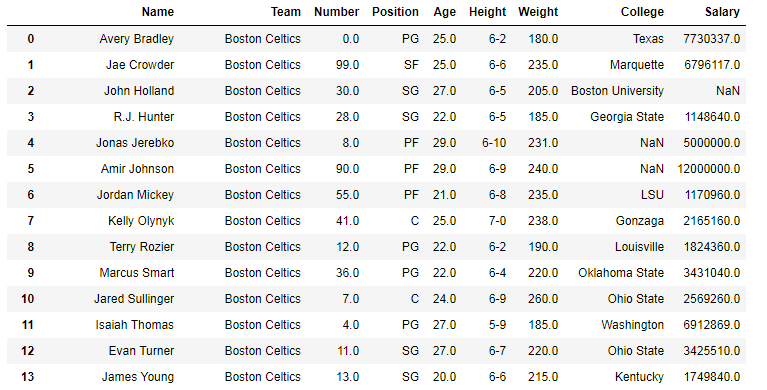
Nos exemplos a seguir, o DataFrame usado contém dados de alguns jogadores da NBA. Você pode ver as dez primeiras linhas do DataFrame, antes de ser feita qualquer alteração nele, abaixo.
Name Team Number Position Age Height Weight College Salary 0 Avery Bradley Boston Celtics 0.0 PG 25.0 6-2 180.0 Texas 7730337.0 1 Jae Crowder Boston Celtics 99.0 SF 25.0 6-6 235.0 Marquette 6796117.0 2 John Holland Boston Celtics 30.0 SG 27.0 6-5 205.0 Boston University NaN 3 R.J. Hunter Boston Celtics 28.0 SG 22.0 6-5 185.0 Georgia State 1148640.0 4 Jonas Jerebko Boston Celtics 8.0 PF 29.0 6-10 231.0 NaN 5000000.0 5 Amir Johnson Boston Celtics 90.0 PF 29.0 6-9 240.0 NaN 12000000.0 6 Jordan Mickey Boston Celtics 55.0 PF 21.0 6-8 235.0 LSU 1170960.0 7 Kelly Olynyk Boston Celtics 41.0 C 25.0 7-0 238.0 Gonzaga 2165160.0 8 Terry Rozier Boston Celtics 12.0 PG 22.0 6-2 190.0 Louisville 1824360.0 9 Marcus Smart Boston Celtics 36.0 PG 22.0 6-4 220.0 Oklahoma State 3431040.0
Exemplo #1: juntando elementos de string
Neste exemplo, o método Series.str.join() é usado na coluna Name (Série de String). Conforme discutido anteriormente, uma string também é uma matriz de caracteres e, portanto, cada caractere da string será unido ao separador passado usando o método Series.str.join().
# Importando o pacote pandas
import pandas as pd
# Criando um DataFrame a partir
# de um arquivo csv
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# Descartando valores null para evitar erros
data.dropna(inplace=True)
# Juntando string e sobrescrevendo
data["Name"] = data["Name"].str.join("-")
print(data)
Conforme mostrado abaixo, a string na coluna Name foi unida por caracteres com o separador passado.
Name Team Number Position Age Height Weight College Salary 0 A-v-e-r-y- -B-r-a-d-l-e-y Boston Celtics 0.0 PG 25.0 6-2 180.0 Texas 7730337.0 1 J-a-e- -C-r-o-w-d-e-r Boston Celtics 99.0 SF 25.0 6-6 235.0 Marquette 6796117.0 3 R-.-J-.- -H-u-n-t-e-r Boston Celtics 28.0 SG 22.0 6-5 185.0 Georgia State 1148640.0 6 J-o-r-d-a-n- -M-i-c-k-e-y Boston Celtics 55.0 PF 21.0 6-8 235.0 LSU 1170960.0 7 K-e-l-l-y- -O-l-y-n-y-k Boston Celtics 41.0 C 25.0 7-0 238.0 Gonzaga 2165160.0 .. ... ... ... ... ... ... ... ... ... 449 R-o-d-n-e-y- -H-o-o-d Utah Jazz 5.0 SG 23.0 6-8 206.0 Duke 1348440.0 451 C-h-r-i-s- -J-o-h-n-s-o-n Utah Jazz 23.0 SF 26.0 6-6 206.0 Dayton 981348.0 452 T-r-e-y- -L-y-l-e-s Utah Jazz 41.0 PF 20.0 6-10 234.0 Kentucky 2239800.0 453 S-h-e-l-v-i-n- -M-a-c-k Utah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0 456 J-e-f-f- -W-i-t-h-e-y Utah Jazz 24.0 C 26.0 7-0 231.0 Kansas 947276.0 [364 rows x 9 columns]
Neste exemplo, o método Series.str.join() é aplicado a uma série de listas. Os dados na coluna Team são separados em uma lista usando o método Series.str.split().
# Importando o pacote pandas
import pandas as pd
# Criando um DataFrame a partir
# de um arquivo csv
data = pd.read_csv("https://media.geeksforgeeks.org/wp-content/uploads/nba.csv")
# Descartando valores null para evitar erros
data.dropna(inplace=True)
# Dividindo string e sobrescrevendo
data["Team"] = data["Team"].str.split("t")
# juntando com "_"
data["Team"] = data["Team"].str.join("_")
print(data)
Conforme mostrado na saída abaixo, os dados foram divididos em lista usando Series.str.split() e, em seguida, a lista foi unida usando Series.str.join() com o separador “_”.
Name Team Number Position Age Height Weight College Salary 0 Avery Bradley Bos_on Cel_ics 0.0 PG 25.0 6-2 180.0 Texas 7730337.0 1 Jae Crowder Bos_on Cel_ics 99.0 SF 25.0 6-6 235.0 Marquette 6796117.0 3 R.J. Hunter Bos_on Cel_ics 28.0 SG 22.0 6-5 185.0 Georgia State 1148640.0 6 Jordan Mickey Bos_on Cel_ics 55.0 PF 21.0 6-8 235.0 LSU 1170960.0 7 Kelly Olynyk Bos_on Cel_ics 41.0 C 25.0 7-0 238.0 Gonzaga 2165160.0 .. ... ... ... ... ... ... ... ... ... 449 Rodney Hood U_ah Jazz 5.0 SG 23.0 6-8 206.0 Duke 1348440.0 451 Chris Johnson U_ah Jazz 23.0 SF 26.0 6-6 206.0 Dayton 981348.0 452 Trey Lyles U_ah Jazz 41.0 PF 20.0 6-10 234.0 Kentucky 2239800.0 453 Shelvin Mack U_ah Jazz 8.0 PG 26.0 6-3 203.0 Butler 2433333.0 456 Jeff Withey U_ah Jazz 24.0 C 26.0 7-0 231.0 Kansas 947276.0 [364 rows x 9 columns]
Artigo escrito por Kartikaybhutani e traduzido por Acervolima de Python | Pandas str.join() to join string/list elements with passed delimiter.